Linux中实现断点续传的原理
时间:2023-02-07来源:系统屋作者:zhijie
断点续传在现在用得很普遍了,如果没有断点续传,那么下载的东西已经下载了90%,但是中断了下载过程,就要从头开始下载。本文就来简单介绍一下Linux系统中断点续传是怎么实现的。
断点续传的原理
其实断点续传的原理很简单,就是在 Http 的请求上和一般的下载有所不同而已。
打个比方,浏览器请求服务器上的一个文时,所发出的请求如下:
假设服务器域名为 wwww.sjtu.edu.cn,文件名为 down.zip。
GET /down.zip HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-
excel, application/msword, application/vnd.ms-powerpoint, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
Connection: Keep-Alive
服务器收到请求后,按要求寻找请求的文件,提取文件的信息,然后返回给浏览器,返回信息如下:
200
Content-Length=106786028
Accept-Ranges=bytes
Date=Mon, 30 Apr 2001 12:56:11 GMT
ETag=W/“02ca57e173c11:95b”
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:56:11 GMT
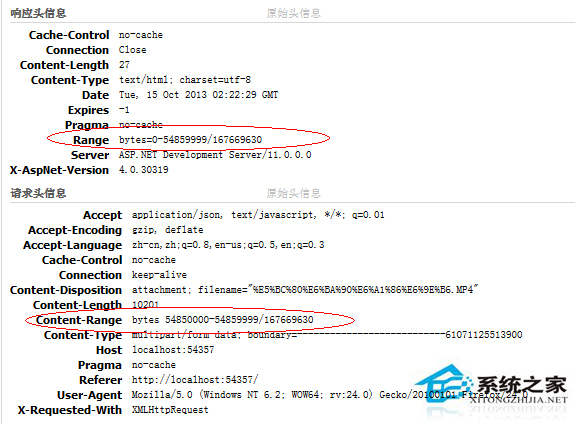
所谓断点续传,也就是要从文件已经下载的地方开始继续下载。所以在客户端浏览器传给 Web 服务器的时候要多加一条信息 -- 从哪里开始。
下面是用自己编的一个“浏览器”来传递请求信息给 Web 服务器,要求从 2000070 字节开始。
GET /down.zip HTTP/1.0
User-Agent: NetFox
RANGE: bytes=2000070-
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
仔细看一下就会发现多了一行 RANGE: bytes=2000070-
这一行的意思就是告诉服务器 down.zip 这个文件从 2000070 字节开始传,前面的字节不用传了。
服务器收到这个请求以后,返回的信息如下:
206
Content-Length=106786028
Content-Range=bytes 2000070-106786027/106786028
Date=Mon, 30 Apr 2001 12:55:20 GMT
ETag=W/“02ca57e173c11:95b”
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:55:20 GMT
和前面服务器返回的信息比较一下,就会发现增加了一行:
Content-Range=bytes 2000070-106786027/106786028
返回的代码也改为 206 了,而不再是 200 了。
知道了以上原理,就可以进行断点续传的编程了。
相关信息
-
-
-
2023-02-07
Linux系统xlsatom命令的使用说明 -
2023-02-06
Linux系统查看文件内容的命令有哪些? -
2023-02-06
Linux日志怎么创建?
-
-
 Linux系统中Git工作流程和基本操作
Linux系统中Git工作流程和基本操作在Linux系统中Git主要用来管理软件的源代码,当然Git也可以用来保存一些死人的文档。本文就阿里介绍一下Linux系统中Git工作流程和基本操作。...
2023-02-06
-
 Ubuntu怎么使用命令管理权限
Ubuntu怎么使用命令管理权限Linux权限管理是一个的专业学问,管理Linux权限的方法有很多,当然也可以用命令来实现这个目的。本文就以Ubuntu为例子,介绍一下Ubuntu怎么使用命令管理权限。...
2023-02-06
系统教程栏目
栏目热门教程
人气教程排行
站长推荐
热门系统下载
- 117次 1 萝卜家园 GHOST XP SP3 极速装机版 V2015.11
- 106次 2 电脑公司 GHOST XP SP3 专业装机版 V2016.10
- 56次 3 雨林木风 GHOST XP SP3 喜迎新年版 V2017.01
- 56次 4 深度技术 GHOST XP SP3 精英装机版 V2015.11
- 55次 5 深度技术 GHOST XP SP3 万能装机版 V2016.01
- 49次 6 新萝卜家园 GHOST XP SP3 电脑城装机版 V2013.1217888
- 43次 7 电脑公司 GHOST XP SP3 装机专业版 V2012.09
- 42次 8 绿茶系统 GHOST XP SP3 通用装机版 V2014.12